Self- supervised Pre-training Models
Self-supervised는 무엇인가?
Self-supervised는 tagged가 있는 문장들을 [Masked]를 통해 스스로 학습하게 하는 것을 말한다.
Self-supervised = pre-training + downstream task 로 나타낼 수 있는데
downstream task 는 문제 종류 분류라고 말 할 수 있다. 즉 목적에 맞게(기계학습, 관계추출 등) 사용 할 수 있다는 것이다.
GPT-1
- GPT series는 테슬라의 Open AI에서 만든 모델이다.
- GPT-1은 simple task뿐만 아니라 다양한 task를 한번에 처리하는 통합된 모델이다.
- GPT-1은 Classification, Entainment, Similarity, Multiple choice 다양한 종류에 따라 구조가 조금씩 다르다.
BERT
- Bidirectional Encoder Representations from Transformer 의 약자
- masked language modeling task(MLM)를 통해 배운다.
- 매우 큰 데이터와 매우 큰 모델을 사용한다.

Model Architecture
- BERT BASE : L=12, H = 768, A = 12
- BERT LARGE: L=24, H= 1024, A = 16
Pre-training Tasks in BERT
Masked Language Model(MLM)
- BERT는 pre-training 과 fine-tuning 사이에 잘못 매치된 것이 발생한다. 마스크를 쓴 토큰은 fine-tuning 동안 나타나지 않기 때문이다.
- 마스크는 보통 15퍼센트의 입력 토큰을 랜덤으로 씌어 마스크 토큰들을 예측한다.(15% 보다 크면 충분한 정보가 주어지지 않으며 15%보다 작으면 encoder 과정에 많은 시간이 필요하고 효율적이지 않다.)
- 15퍼센트의 예측 단어중 80%는 MASK로 대신하고 10%는 랜덤 단어로 대신하고 10%는 같은 문장을 유지한다.
Next Sentence Prediction (NSP)
- 문장간의 관계에 대해서 학습할 때 뒷 문장이 앞에 문장과 이어지는 문장인지, 랜덤문장인지 예측을 할 수 있어야한다.
A Binarized next sentence prediction task that can be trivially generated from any monolingual corpus is trained.
- 50% of the time B is the actual next sentence that follows A (Is Next)
- 50% of the time it is random sentence from the corpus(Not Next)
C is used for next sentence prediction.
Despite its simplicity, pretraining towards this task is very beneficial both QA and NLI
BERT의 Input embedding = Token Embeddings + Segment Embeddings + Position Embeddings 이다.


| BERT | GPT-1 | |
| BookCorpus | 2,500M words | 800M words |
| Batch size | 128,000 words | 32,000 words |
| learning rate | choose a task-specific fine-tuning learning rate | 5e-5 for all fine-tuning |
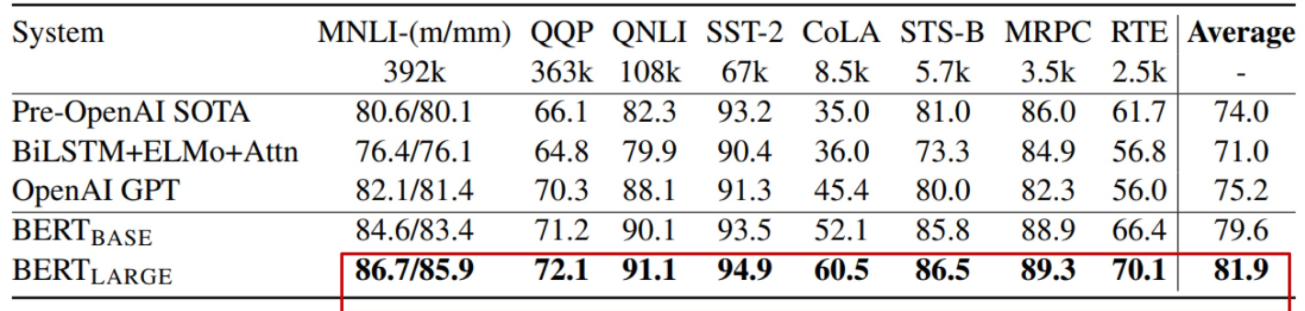
BERT : Ablation Study
많은 데이터와 파라미터는 성능을 올리는데 많은 도움을 준다.

'AI-Tech 부스트캠프 > NLP' 카테고리의 다른 글
| [NLP] Bag of Words (0) | 2023.01.18 |
|---|---|
| [NLP] Advanced Self-supervised Pre-training Models (0) | 2021.09.18 |
| [NLP] Transformer (0) | 2021.09.14 |
| [NLP] Basics of Recurrent Neural Networks(RNNs) (0) | 2021.09.10 |
| [NLP] 자연어처리란? (0) | 2021.09.06 |


댓글