사실 이전에 [DL]에서 배운 적이 있어서 쓴 적이 있다.
아래를 먼저 참고하는 것이 좋다.
https://thought-process-ing.tistory.com/5
[DL] Recurrent Neural Networks(RNN), Transformer
Recurrent Neural Networks(RNN) RNN은 주어진 모델 자체가 Sequential Model이다. 즉 연속된 순서가 존재하는 모델로 비디오, 텍스트등이 여기에 속한다고 생각하면 된다. Sequential Data에서의 RNN 모델의 성능은
thought-process-ing.tistory.com
RNN
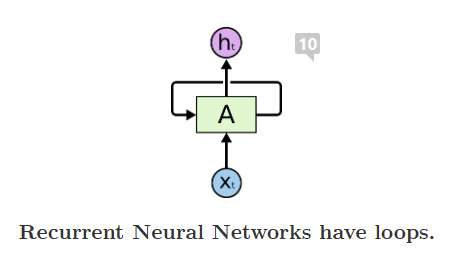
Basic structure:
Rolled Version RNN 과 Unrolled version RNN으로 표현할 수 있다.(등식을 보면 알겠지만 사실 두개는 같은 것이다.)

이 구조를 조금 더 이해해보자.

따라서 수식을 다음과 같이 쓸 수 있다.

내부 계산하는 방법이 아직 잘 보이지 않을 수 있다.
아래 그림을 보면 $h_{t-1}$과 $X_{t}$를 각각 어떤 행렬($W_{hh}$, $W_{xh}$)을 이용해 선형변환을 한 후 Non-linear-Activation(비선형 활성화 함수)를 이용해 새로은 $h_{t}$를 추출 할 수 있음을 알 수 있다.

따라서 식으로 표현하면

그리고 출력 값
$y_{t}$ = $W_{hy} h_{t}$로 표현 할 수 있다.
Types of RNNs
Sequential Data는 여러가지 구조가 있을 것이다.
크게 5가지로 나누어 볼 수 있다.

위 5가지를 보면 다른점이 크게 input과 ouput의 위치를 볼 수 있다.
● One - to - one
- Standard Neural Networks
● One - to - many
- Image Captioning (이미지를 통해 특징들(features) 추출)
● Many - to - one
- Sentiment Classification ( ex) : Positive/Negative)
● Many to many
- Machine Translation ( ex): I go home. → 나는 집에 간다.)
● many to many
- Video classification on frame level
사용 목적에 따라 마지막 출력 구조가 모두 다를 것이다.





이를 통해
Loss 를 계산할 수 있다.


RNN 의 치명적 단점
RNN은 좋은 성능을 가지지만 Vanish Gradient Problem을 가질 수 있다. 왜냐하면 비선형 함수 tanhx를 계속 쓰면 어느순간 0이 될 수가 있다.


Train에서 backpropagation에서 gradient vanish가 일어나면 weight(W행렬)의 optimizer를 찾기 어렵다.
무슨 말이냐면 위의 tanh(x) 그래프에서 x가 -1 과 1 차이는 매우 큰 반면 x가 4와 6의 차이는 매우 작다.
그러면 loss를 통해 weight의 수정을 하기 어렵다.
그래서 나온 것이?
LSTM, GRU 이다!
잠깐 보면

LSTM(Long Short-Term Memory)은?
Cell State를 통해 어떠한 선형변환도 없이 정보를 바로 전달한다.
- 이는 장기 기억 의존 (long-term dependency) 문제를 해결한다.


GRU(Gated Recurrent Unit)
LSTM을 경량화 하여 적은 메모리를 요구하고 빠른 계산시간이 장점이다.

'AI-Tech 부스트캠프 > NLP' 카테고리의 다른 글
| [NLP] Bag of Words (0) | 2023.01.18 |
|---|---|
| [NLP] Advanced Self-supervised Pre-training Models (0) | 2021.09.18 |
| [NLP] Self-supervised Pre-training Models (0) | 2021.09.18 |
| [NLP] Transformer (0) | 2021.09.14 |
| [NLP] 자연어처리란? (0) | 2021.09.06 |


댓글