
Tensor handling
view, squeeze, unsqueeze 등으로 Tensor을 조정할 수 있다.
- view: reshaper과 동일하게 tensor의 shape을 변환
- squeeze: 차원의 개수가 1인 차원을 삭제(압축) ex) $ 2 \times 2 \times 1$ 행렬을 $ 2 \times 2$ 행렬로 변환
- unsqueeze: 차원의 개수가 1인 차원을 추가

그럼 view와 reshape의 차이는 무엇일까?
view는 contigious(인접한)것이 아니면 사용할 수 없다는 것이다.
contigious는 무엇을 이야기 할까?
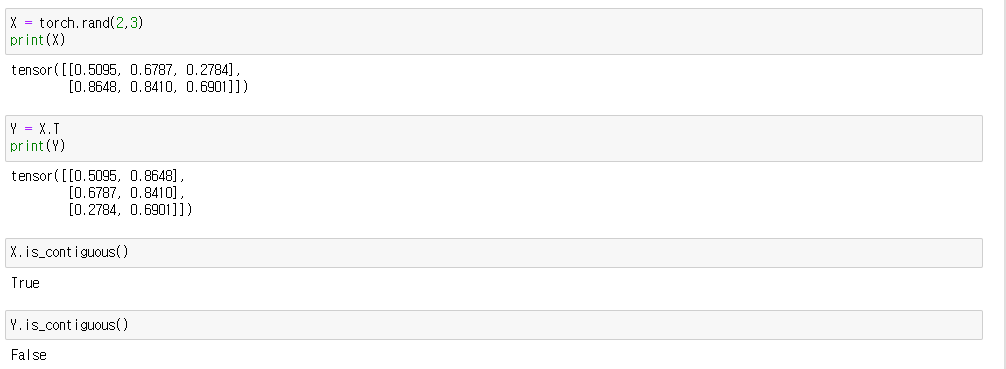
각 원소별로 메모리 주소를 보자

X, Y 모두 torch.float32 자료형은 4바이트이므로, 메모리 1칸 당 주소 값이 4씩 증가한다.
X는 메모리 순서대로 4바이트씩 늘어나지만 Y는 그렇지 않다. 이는 X는 메모리 순서대로 읽는 방면, Y는 메모리 순서대로 읽지 않는다는 것을 알 수 있다.
즉 X는 메모리 순서대로 읽기 때문에 view 사용 가능하지만 Y는 메모리 순서대로 읽지 않기 때문에 view 사용을 할 수 없다.

view는 메모리 순서대로 데이터를 읽을 때만 사용할 수 있다.
Squeeze와 Unsqueeze에 대해서

잘 보면 알겠지만 Unsqueeze()는 안에 숫자에 따라 차원을 늘릴 방향을 정할 수 있다.

squeeze()는 차원의 개수가 1인 차원을 모두 삭제한다.

Tensor operations
행렬 곱셈 연산 'dot' vs 'mm' vs 'matmul'
dot와 mm과 matmul을 계산해보면 dot는 곱셈연산을 사용할 수 없다.

mm과 matmul의 차이점은 mm은 broadcasting을 지원 안한다는 것이고 matmul은 broadingcasting을 지원한다는 것이다.

Broadcasting은 텐서에 대해서 사칙 연산을 수행할 때 자동적으로 크기를 맞춰서 연산을 수행하게 만드는 기능을 말한다.
import torch
m1 = torch.FloatTensor([[1,2]])
m2 = torch.FloatTensor([3])
# m1 + m2 = [1,2] + [3] = [1,2] + [3,3] = [4,5] 이와 같은 것을 broadcasting 지원이라고 말한다.Tensor operations for ML/DL formula
nn.functional 모듈을 통해 다양한 함수를 제공한다.

AutoGrad
PyTorch의 가장 큰 핵심중 하나인 자동 미분(AutoGrad) 지원한다는 것이다.

다음과 같은 행렬이 있다고 가정하자.
$$\begin{bmatrix}a_{1} & a_{2} \\b_{1} & b_{2} \end{bmatrix}$$
$Q =3a^3 - b^2$ 를 a, b에 대해서 autograd를 확인하려고 한다.

'AI-Tech 부스트캠프 > 파이토치' 카테고리의 다른 글
| [PyTorch] torch.transpose()와 numpy().transpose() 차이 (0) | 2023.01.01 |
|---|---|
| [PyTorch] 모델 불러오기 (0) | 2022.12.24 |
| [PyTorch] Dataset & Dataloaders (0) | 2022.12.24 |
| [PyTorch] torch.nn.Module에 대해서 (0) | 2022.12.24 |
| [PyTorch] 파이토치에 대해서 알아보자 (0) | 2022.12.23 |




댓글