합성 곱(Convolution)
Continuous convolution
○ $(f \ast g)(t) = \int f( \tau )g(t- \tau ) d \tau = \int f(t- \tau )g( \tau ) d \tau$
Discrete convolution
○ $(f \ast g)(t) = \sum_{i=- \infty }^ \infty f( \tau )g(t- \tau ) = \sum_{i=- \infty }^ \infty f(t- \tau )g( \tau )$
2D image convolution
○ $(I \ast K)(i, j) = \sum_{m} \sum_{n} I(m,n)K(i-m, j-n) = \sum_{m}\sum_{n} I(i-m,j-n)K(m,n)$
Convolution Layer : Convolution Layer은 Receptive Field를 정의하여 input 층의 이미지의 Feature을 추출하는 역할을 한다. 이 때 이미지 픽셀 값, Receptive Field의 Weight의 선형 결합으로 한 개가 나타난다.
CONV1d

CONV2d
$ O_{11} = K_{11} \times I_{11} + K_{12} \times I_{12} + K_{13} \times I_{13} + K_{21} \times I_{21} $
$+ K_{22} \times I_{22} + \, K_{23} \times I_{23} + K_{31} \times I_{31} + K_{32} \times I_{32} + K_{33} \times I_{33} + bias$

2D convolution을 보면 RGB 색 등 여러가지 방법으로 표현 될 수 있다. 이를 chanel을 통해 합성할 수 있다.

CNN : Region Feature를 뽑아내는 Convolution Layer와 Feature Dimension을 위한 Pooling Layer 그리고 최종적인 분류를 위한 Fully connected Layer(FC)로 구성 돼 있다.

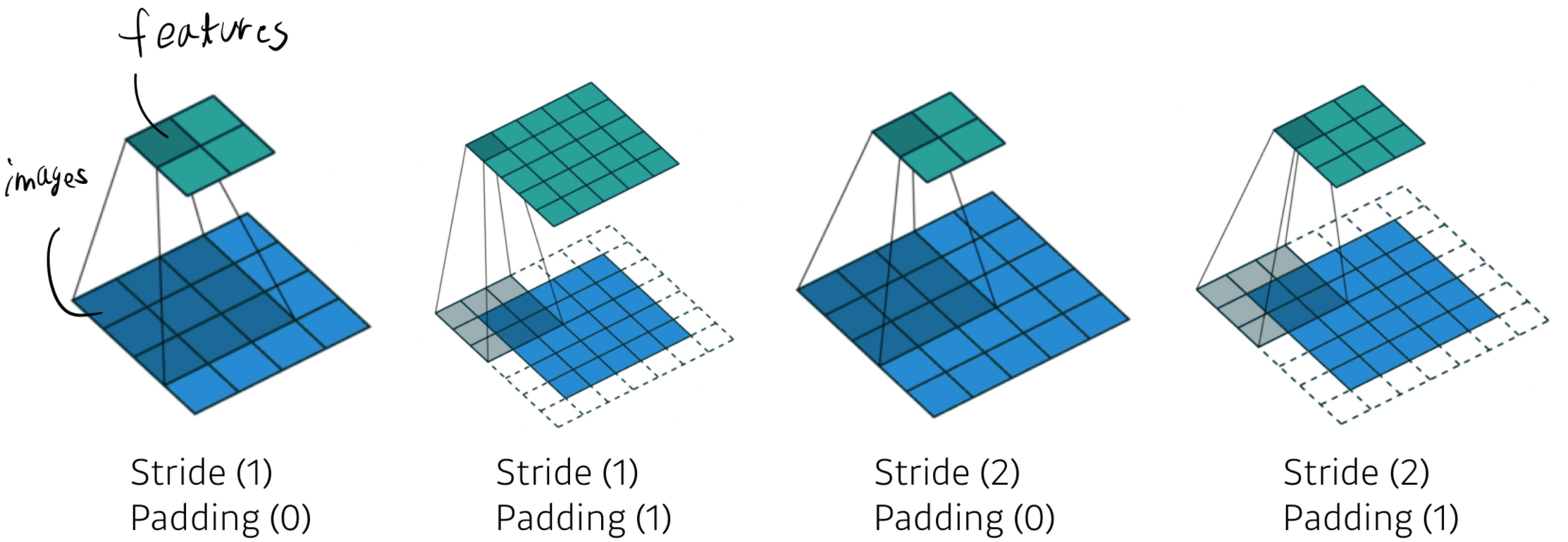
stride : Convolution Layer에서 Receptive field가 이미지를 돌면서 Feature을 뽑을 때 이동하는 칸 수
Padding : Image Size를 줄이지 않고 모든 픽셀 값에 Convolution을 적용하기 위해 적용하는 개념으로 기본 이미지 사이즈의 테두리에 0값을 넣어 이미지의 사이즈를 유지하고 테두리에 있는 픽셀 값도 안에 있는 픽셀 값과 똑같이 Convolution을 거치도록 하는 것이다.
1 x 1 Convolution 쓰는 이유
CNN 모델을 보다보면 1 x 1 Convolution kernel을 쓰는 것을 종종 볼 수 있다. 1 x 1 Convolution kernel은 아키텍처 설계에 에 있어서 몇 가지 도움을 준다.
- width, height 변화 없이 channel의 수를 조절할 수 있다. ( ex: Dimension reduction, reduce the number of parameters)
- width, height, channel 변화는 없지만 비선형 함수를 쓰고 좀 더 좋은 모델을 만들 수 있다.
Modern CNN
ILSVRC : ImageNet Large-Scale Visual Recognition Challenge를 뜻하며 2015년 기점으로 인간의 성능을 넘어 네트워크의 깊이는 152층에 이르었다고 한다.
AlexNet : 2012년 ILSVRC 대회 우승 모델로 224x224 크기의 RGB 3 Channel Image를 Input으로 사용했고 Activation 함수로는 ReLU를 사용, Data augmentation과 Dropout를 적용 2개의 GPU를 사용했다.
VGG : ILSVRC 2014.에서 2위를 차지. 3x3 convolution Layer를 깊게 중첩한다는 것이 특징. 1x1 convolution을 fully connected layers에 사용. parameter 수를 width&height에서 줄임. 깊이에 따라 VGG16, VGG19라 불림
GoogLeNet : ILSVRC 2014에서 우승. Inception blocks로 1x1 convolution을 사용해 channel dim을 줄여 parameter의 수를 많이 줄였다.
ResNet : ILSVRC 2015에서 우승. 지금까지도 이미지 분류의 기본 모델로 널리 쓰이고 있다. Residual Block이라는 개념을 도입. 네트워크가 깊어짐에 따라 앞 단의 Layer에 대한 정보는 뒤의 Layer에서는 희석될 수 밖에 없는데 이러한 단점을 해결하기 위해 'Skip Connection'이라는 것을 이용해 이전의 정보를 뒤에서도 함께 활용할 수 있도록 함.
DenseNet : DenseNet은 ResNet의 확장된 버전이다. ResNet은 이전 Layer와 다음 Layer에 SKip Connection을 적용하는 모델이라면 DenseNet은 모든 Layer에 Skip Connection을 적용하는 모델이다.
Computer Vision Application
Semantic Segmentation
- 이미지의 각 픽셀을 분류한다.
- 자율주행에 많이 쓰인다.
Fully Convolutional Network(FC)

일반적인 CCN은 마지막에 flat시키고 dense시키지만 Convolutionalization을 통해 Convolution 연산처럼 변환
# of parameters는 변하지 않는다. (왼쪽: 4*4*16*10 = 2560, 오른쪽: 4*4*16*10 = 2560)
※참고로 Transforming fully connected layers into convolution layers는 분류 net을 히트맵(heat map) 결과로 도출시킬 수 있다.
Deconvolution(conv transpose)
일반적으로 convolution을 복원하는 것은 불가능
엄밀히 말하는 역연산은 아님
하지만 역연산이라고 생각하면 편하다. Parameter 숫자나 Net 상으로 같음

'AI-Tech 부스트캠프' 카테고리의 다른 글
| 2021_08_14_(토) (0) | 2021.08.14 |
|---|---|
| [DL] Generative Models (0) | 2021.08.13 |
| [DL] Recurrent Neural Networks(RNN), Transformer (0) | 2021.08.12 |
| [DL] 최적화 (Optimization) (0) | 2021.08.10 |
| [DL] 딥러닝의 역사 (0) | 2021.08.09 |




댓글