1) 크롬 정보 확인
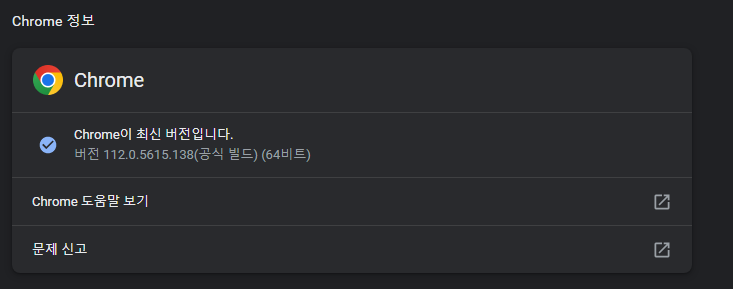
2) webdriver 설치
아래 사이트 들어가서 버전에 맞는 크롬을 설치한다.

https://chromedriver.chromium.org/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 113, please download ChromeDriver 113.0.5672.24 If you are using Chrome version 112, please download ChromeDriver 112.0.5615.49 If you are using Chrome version 111, please download ChromeDriver 111.0.5563.64
chromedriver.chromium.org

그러면 준비는 끝!
파이썬 selenium을 이용하서 데이터 크롤링 할 것이다.
네이버 증권의 다음 네모박스란을 크롤링해보겠다.
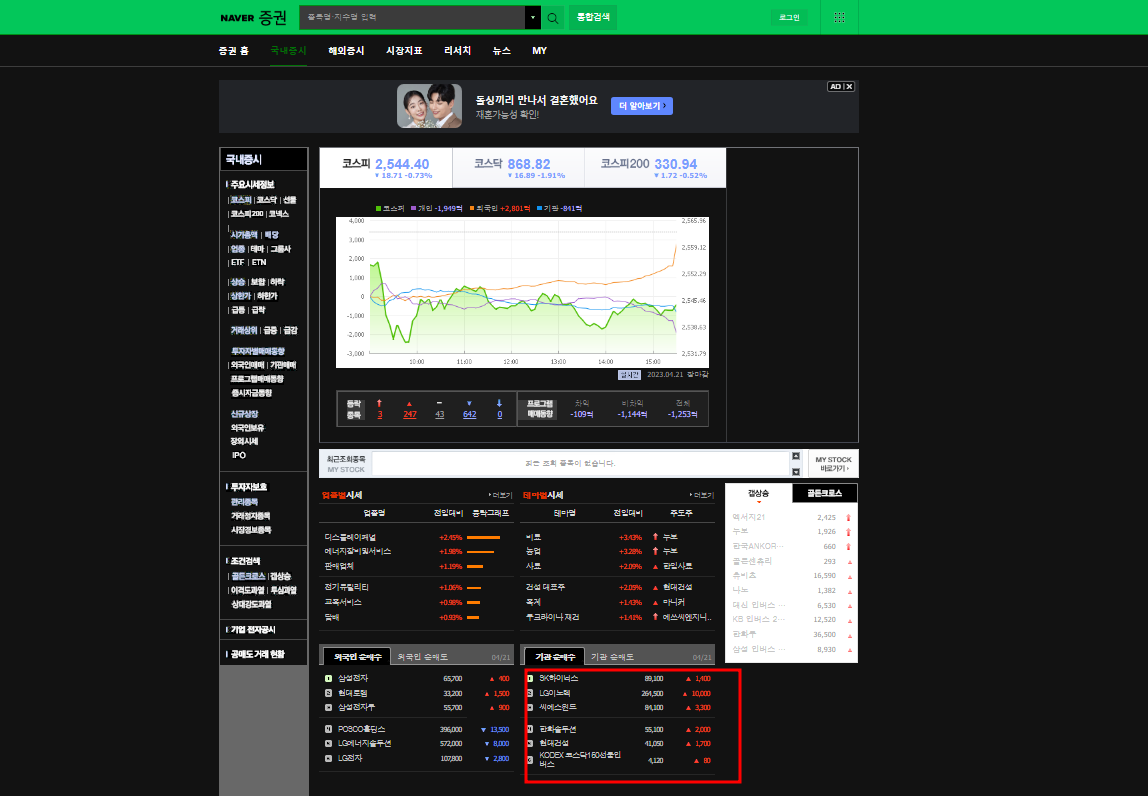
'ctrl' 'shift' 'i' 를 눌러서 개발자도구를 연다.

파란부분을 세분화하여 원하는 부분이 파란색으로 되어있으면 마우스를 눌러 세부적인 코드로 들어간다.

완전 세분화하여 내가 원하는 텍스트만 파란색으로 되어있을 때 마우스 오른쪽 부분을 눌러 copy의 copy_Xpath를 누른다.
그리고 아래 코드처럼 driver.find_element_by_xpath('copy_Xpath').text에 넣어 원하는 텍스트를 가져올 수 있다.
CODE(원하는 부분을 크롤링하여 데이터프레임으로 만든 다음 csv파일로 만들었다.)
from selenium import webdriver
import pandas as pd
import urllib.request
driver = webdriver.Chrome(executable_path='C:/Users/singo/Downloads/chromedriver_win32/chromedriver.exe')
driver.get('https://finance.naver.com/sise/')
# driver.find_element_by_xpath('//*[@id="NM_NEWSSTAND_HEADER"]/div[2]/a[3]').click()
#driver.implicitly_wait(10)
driver.find_element_by_xpath('//*[@id="contentarea_left"]/div[2]/table/tbody/tr[3]').text
num_list = []
name_list=[]
price_list=[]
increase_list=[]
for i in range(2,11):
if i in [5,6,7]: continue
number = driver.find_element_by_xpath('//*[@id="organ_deal_tab_0"]/tbody/tr['+str(i)+']/td[1]/img')
number_url = number.get_attribute('src')
urllib.request.urlretrieve(number_url,'image'+str(i)+'.png') # 이미지 따로 저장
num_list.append(number_url)
name = driver.find_element_by_xpath('//*[@id="organ_deal_tab_0"]/tbody/tr['+str(i)+']/td[2]/a')
name_list.append(name.text)
price = driver.find_element_by_xpath('//*[@id="organ_deal_tab_0"]/tbody/tr['+str(i)+']/td[3]')
price_list.append(price.text)
increase = driver.find_element_by_xpath('//*[@id="organ_deal_tab_0"]/tbody/tr['+str(i)+']/td[4]/span')
increase_list.append(increase.text)
df = pd.DataFrame({'등수':num_list,'기업명':name_list,'가격':price_list,'증가율':increase_list})
df.to_csv(path_or_buf='C:/Users/singo/Downloads/chromedriver_win32/stock.csv',header=['등수','기업명','가격','증가율'],encoding='cp949',index=False)
print(df.head())
print('finish!')
driver.quit() # 자동으로 꺼짐
사실 개발자도구 내용을 알아야 더 이해하기 쉽고 오래간다.
필자는 HTML을 모르는 상태로 많이 어려웠었는데... 아는상태여도 기록하기 역시 어렵다.
요즘 유튜브도 잘 나오고 내가 알아볼 수는 있으므로 여기서 정리 끝!
'데이터 분석' 카테고리의 다른 글
| [데이터 분석] 2023 LCK_스프링 챔피언 분석(01.18~01.19) (1) | 2023.01.20 |
|---|

댓글